
La funzione del rischio si basa su tre fattori: minaccia, vulnerabilità e impatto. Implicito ma decisamente importante è l’oggetto della vulnerabilità su cui la minaccia si può abbattere per provocare poi un impatto. Un semplice esempio potrebbe essere un ladro (attore della minaccia) che utilizza un piede di porco (strumento della minaccia) per aprire una porta di un magazzino (oggetto), per rubare un attrezzo (impatto). In questo caso, non viene esplicitata la vulnerabilità che è intrinseca all’oggetto. Se la porta fosse blindata e chiusa a mandate, probabilmente sarebbe meno vulnerabile al piede di porco, utilizzato dal ladro. Se la porta fosse chiusa con un semplice chiavistello, sarebbe molto più vulnerabile. Traslato nel mondo cyber potremmo vederla così: un gruppo criminale (attore della minaccia) utilizza un exploit (strumento) per entrare in un server (oggetto) e rubare delle informazioni (impatto).
La vulnerabilità è intrinseca al server. Se sul server e sugli applicativi in esso contenuti, fosse stato attuato un processo di patching aggiornato, sarebbe meno vulnerabile a potenziali exploit. Consideriamo tutti i fattori singolarmente:
- Minaccia che potremmo vedere composta dall’attore e dagli strumenti da esso utilizzato e le tecniche, tattiche e procedure;
- Vulnerabilità comprensiva anche dell’informazione sull’oggetto interessato dalla vulnerabilità stessa;
- Impatto che è il danno subito e si esplicita in una interruzione di servizio, in un furto di informazioni e conseguenti perdite economiche.
Questi tre fattori, costituiti a loro volta da più sotto-fattori, sono fondamentali per il calcolo del rischio. Il calcolo del rischio fino a qualche anno fa, ma ancora oggi in qualche azienda, è un processo il cui risultato è una fotografia. Si calcola il rischio una volta all’anno, se va bene, e si fotografa il livello per poi definire i piani di rientro. I meno fortunati si ritrovano in mano un risultato qualitativo (alto, medio, basso), mentre i più fortunati con un valore quantitativo. Il processo del rischio fa partire dei piani di rientro per mitigare e ridurre quanto più possibile il rischio stesso.
Questo poteva andare bene in un mondo in cui la velocità e il cambiamento dei fattori concomitanti alla valutazione del rischio erano relativamente bassi. Nel 2022, sono uscite in media più di 60 vulnerabilità al giorno, per non parlare dei malware che possono annoverare decine di migliaia di varianti giornaliere e gli stessi asset tecnologici (e non) a supporto dei servizi sono in continuo cambiamento. Pertanto, è necessario strutturarsi in modo tale da poter monitorare costantemente l’evoluzione del rischio ed essere in grado di mitigare per quanto sia possibile lo stesso, attraverso un approccio real-time.
Da cosa partire? Sicuramente dal comprendere cosa si deve difendere. Il mio punto di partenza, nel caso si parli di un’azienda privata, sarebbe il bilancio aziendale d’esercizio. Questo documento, spesso sottovalutato, presenta una serie di informazioni utili a comprendere cosa si deve difendere. All’interno del bilancio d’esercizio ci sono informazioni sui ricavi, da quali linee produttive o di servizi questi vengono prodotti, quanto personale c’è in azienda, quali aree geografiche interessano il business dell’azienda, l’organizzazione e così via. Supponiamo di concentrarci solo sui servizi che generano ricavi. Isolando solo le informazioni sulla produzione dei ricavi, l’attività successiva è scendere quanto più possibile nelle informazioni a supporto: marginalità, canali di vendita del prodotto o del servizio e da qui poi procedere con l’approfondimento all’interno dell’azienda su quali siano gli asset propedeutici alla produzione dei ricavi.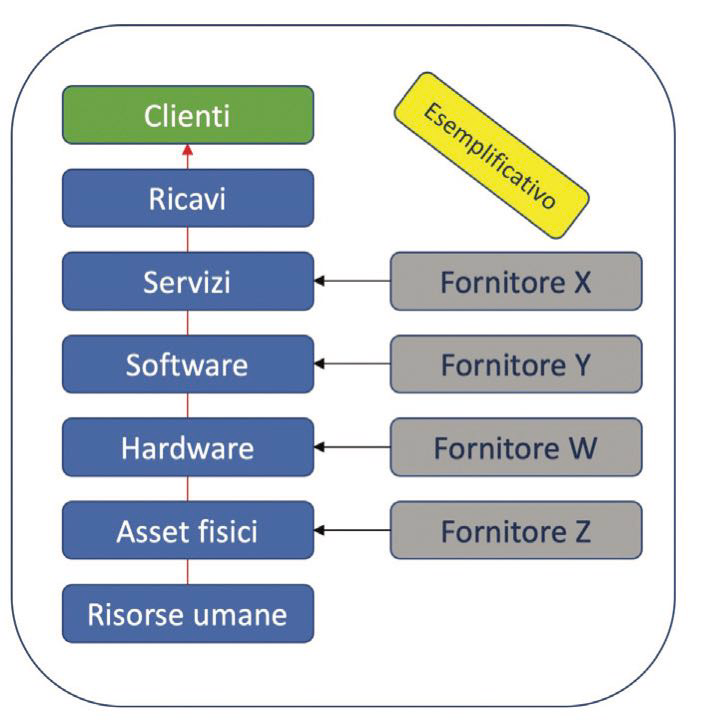
I ricavi sono generati da servizi/prodotti, erogati attraverso canali, supportati da asset informatici (hardware e software) e asset fisici (data center, uffici, stabilimenti) attraverso il lavoro del personale aziendale e il supporto di fornitori e del loro personale. L’ideale sarebbe tracciare i ricavi in base al servizio erogato near real time sui sistemi per comprendere il flusso e le eventuali interruzioni e di conseguenza le perdite dirette a livello economico (operazioni effettuate sui canali digitali; consumi energetici e relativo valore economico; acquisti online; …). Se non fosse possibile, anche l’analisi dello storico potrebbe aiutare per dare un’idea dei flussi. In alcuni casi, se si considera canoni mensili fissi, le perdite potrebbero essere stimate in base al tasso di churn dei clienti associabili ai disservizi e l’impatto anche in ricavi mancati per cattiva pubblicità. Sono solo esempi. Stabilito il perimetro del servizio (catene tecnologiche, asset fisici, personale e fornitori, …) si passa a verificare quali minacce e vulnerabilità possano impattare sullo stesso.
L’identificazione del perimetro è forse la parte più dispendiosa delle attività in termini temporali e relazionali. Questo processo può essere supportato da precedenti analisi del rischio, controlli audit, che possono costituire una base di partenza dell’analisi. È un lavoro che richiede un approccio multidisciplinare. Il perimetro è il fulcro del sistema di valutazione del rischio. La funzione del rischio rimane sempre la stessa, sono le tempistiche della sua applicabilità che cambiano e il perimetro informativo che si ampia. Invece di essere una fotografia statica annuale, mensile, o periodica la funzione del rischio dinamico viene popolata continuamente da informazioni che ne cambiano, eventualmente, il risultato. Il popolamento avviene attraverso flussi costanti di informazioni che devono poi essere verificati, normalizzati, contestualizzati per poi fornire degli input allo scenario del rischio. In questo modo, lo scenario del rischio viene ricalcolato in base all’input fornito. Il sistema richiede, innanzitutto, la capacità di immagazzinare e trattare una grande mole di dati e capacità computazionali per elaborarle.
I dati, almeno in questa prima fase, devono essere normalizzati e strutturati per permetterne la continua correlazione. Una volta stabilite le correlazioni da effettuare, è necessario anche inserire degli algoritmi in grado di pesare l’informazione. Ad esempio, pesare di più gli asset propedeutici all’erogazione di servizi che generano maggiori ricavi o margini più alti. Attenzionare maggiormente le CVE che hanno un’alta probabilità di sfruttabilità, attraverso la creazione di algoritmi probabilistici, e prioritizzarle maggiormente nel momento in cui le fonti di intelligence annoverano l’utilizzo delle stesse da particolari gruppi criminali. La cosa più vicina e associabile al perimetro, è la vulnerabilità, sfruttabile da una minaccia, come rappresentato nella figura sopra. Stessa cosa per le tattiche e tecniche di attacco, andando a prioritizzarne il monitoraggio in base al maggior utilizzo da parte dei criminali.
Se più criminali utilizzano le stesse TTP, allora sarebbe una buona pratica quella di identificare le tecniche maggiormente utilizzate e verificare se ci sono gli strumenti idonei per monitorare l’infrastruttura interna alla ricerca di riscontri.
Allargando il perimetro di monitoraggio, si devono creare dei sistemi di monitoraggio dei fornitori, sia attraverso l’utilizzo di sistemi di valutazione sia grazie al monitoraggio delle fonti di intelligence che possono rilevare potenziali compromissioni, sia attraverso sistemi propri o di terze parti che ne valutano la postura di sicurezza online in real time. Un collegamento con il database preposto alla registrazione dei fornitori e dei relativi contratti permetterebbe di ricevere i dati delle aziende fornitrici e trovare correlazioni con altre fonti di intelligence (in caso di attacchi che le riguardino), ma anche permetterebbe poi di verificare se vi siano utenze personali o collegamenti LAN to LAN fra le due aziende confrontando i dati con i DB di reti e dell’Active Directory. Inoltre, permetterebbe di monitorare anche eventuali flussi email provenienti dai domini delle aziende colpite dall’attacco (dove questo fosse possibile in termini normativi e tecnici).
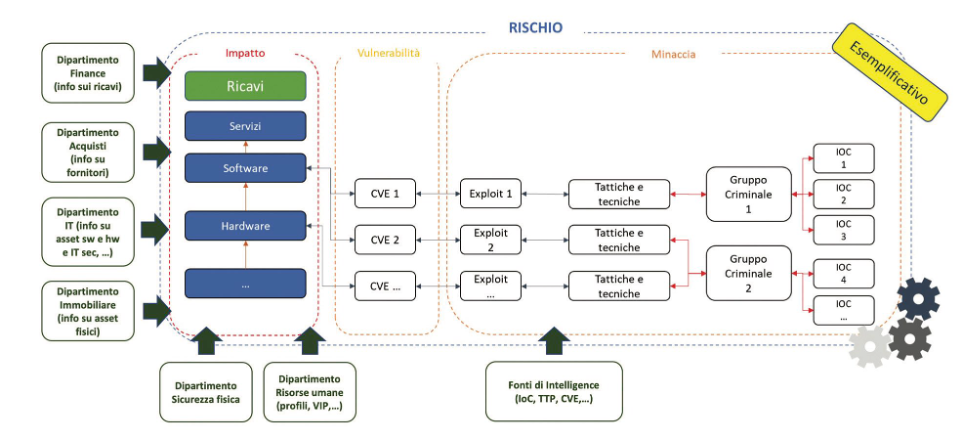
Un esempio di scenario di alto livello: Supponiamo di ricevere una informativa relativa ad un gruppo criminale specifico che mira a colpire aziende nel nostro settore e nella nostra area geografica. Inserendo questo nuovo input nel nostro sistema di calcolo dinamico del rischio, mi aspetterei:
- Ricezione da parte delle fonti informative delle informazioni collegate al gruppo criminale: IoC, CVE sfruttate, TTP;
- Dal sistema di asset verificherei se le CVE, sfruttate dal gruppo criminale, sono presenti sui miei asset e quale servizio vi è associato. Se le CVE sono già in un piano di patching, se ci sono contromisure specifiche in essere e così via;
- Riuscirei a determinare il valore economico delle perdite in caso quell’asset venisse attaccato in base a un potenziale blocco del servizio oppure in base alle informazioni in esso contenute;
- Dai sistemi perimetrali verificherei se gli IoC collegati al gruppo criminale sono riconosciuti oppure no;
- Verificherei se ci sono informazioni relative alle TTP, soprattutto per identificare quali tecniche solitamente usano per i movimenti trasversali e se ho la possibilità di identificare eventuali eventi che mi possano allertare al riguardo;
- Verificherei quali sono gli Amministratori di Sistema che possono accedere a quegli asset e se ci siano stati tentativi di contatto, via email, verso di loro da attori malevoli o se risultano delle anomalie comportamentali di accesso degli stessi;
- Verificherei se fra gli annunci o le informative degli attacchi, effettuati dal gruppo criminale, compaiono anche nostri fornitori.
Queste serie di verifiche mi dovrebbero portare ad un livello di rischio e permettere anche di identificare quali azioni mettere in essere per ridurlo. Ad esempio, prioritizzare un patching, bloccare degli IoC non ancora identificati dai sistemi, chiudere delle utenze di fornitori o delle LAN to LAN fino a incidente rientrato e così via. Il valore del rischio rimarrebbe uguale fintanto che un ulteriore input lo vada a modificare: una CVE associata a un gruppo; una nuova CVE pubblicata; ulteriori IoC aggiornati e attribuiti ad un gruppo; un asset cambiato o la postura di sicurezza di un nostro fornitore peggiorata. L’esempio non è esaustivo e probabilmente approssimativo.
 Il concetto che si vuole esprimere è quello di continuità di elaborazione in modo da rendere dinamico anche il calcolo del rischio. Ogni input deve essere recepito automaticamente dal sistema e deve rielaborare immediatamente il calcolo del rischio. Per questo è necessario un lavoro pesante a monte per strutturare le informazioni e creare i canali di approvvigionamento. L’interpretazione del dato stesso ha un ruolo rilevante. In alcuni casi è necessario individuare anche i giusti partner, soprattutto per quanto riguarda le fonti di intelligence.
Il concetto che si vuole esprimere è quello di continuità di elaborazione in modo da rendere dinamico anche il calcolo del rischio. Ogni input deve essere recepito automaticamente dal sistema e deve rielaborare immediatamente il calcolo del rischio. Per questo è necessario un lavoro pesante a monte per strutturare le informazioni e creare i canali di approvvigionamento. L’interpretazione del dato stesso ha un ruolo rilevante. In alcuni casi è necessario individuare anche i giusti partner, soprattutto per quanto riguarda le fonti di intelligence.
Le fonti di intelligence sono preziose per tutte le informazioni che riguardano minaccia e vulnerabilità ma spesso richiedono un lavoro di normalizzazione elevatissimo in quanto il dato non è strutturato e quindi poco usufruibile in maniera automatizzata nei propri sistemi. La creazione di un sistema Big Data Analytics in grado di contenere numerose informazioni è un’attività dispendiosa. Identificare i database; trovare il modo in cui agganciarli, verificare la consistenza delle informazioni, creare le giuste query, automatizzarle e definire gli alert, non è semplice. Pertanto, è necessario avere le idee chiare e gli obiettivi di analisi che si vuole raggiungere in modo da portare a casa dei risultati a fasi successive. Quindi è necessario dotarsi di pazienza e tanto spirito di sacrificio.
Autore: Massimo Cappelli




